
Magazin Google Search Console Advanced
Nach dem vielen positiven Feedback von meinem SEOkomm-Vortrag am 18.11.2016 folgt hier eine schriftliche Zusammenfassung. Du findest ein paar weiterführende Informationen und Tipps, wie Du noch mehr aus der Google Search Console (GSC) herausholen kannst. Vielen Dank an dieser Stelle auch an mein Team – durch das Entwickeln des GSC-Tools serplorer und die Agenturarbeit haben wir eine Menge Dinge sehr genau betrachtet und viele Erfahrungen gesammelt, an denen Du nun teilhaben kannst. Viel Spaß!

Inhaltsverzeichnis
- Datenlimits umgehen – die richtige Propertyverwaltung
- robots.txt-Tester
- Ansicht zu interne Links nicht für interne Verlinkungsoptimierung nutzen
- Erkennung von Fehlern der Hreflang-Gruppen nutzen
- URL-Entfernen ist eigentlich URL-Ausblenden
- Fast-Disavow zu Zeiten von Realtime-Pinguin
- Crawlingfehler - trau dich
- Verstärktes Crawling ist Hinweis auf Update oder stärkere Rankingänderung
- Crawlbudget und die GSC-Ansicht
- GSC Search Analytics – Fakten
- Durchschnittliche Rankings
- Obacht bei der Wahl der Analyse: Seiten vs. Suchanfragen
- Bereinigung der Suchdaten
- Mehrfachranking und Schwellenkeywords
- Die Google Search Console-API
- GSC-API ohne Programmierkenntnisse
- GSC-Tweak: Nicht indexierte URLs über die GSC anzeigen lassen
- Für ganzheitlichen Erfolg im Online Marketing
- Gemeinsam widmen wir uns Ihren SEO-Potenzialen!
Datenlimits umgehen – die richtige Propertyverwaltung
Die GSC liefert je Property leider nicht alle verfügbaren Daten aus. Meistens werden nur 1.000 Datensätze im Frontend angezeigt. Es gibt aber eine relativ einfache Möglichkeit, wie man diese Grenze einerseits umgehen kann und andererseits auch die Datenauswertungen granularer machen kann.
Property-Ebenen
Man kann statt einer Property für die Domain einfach mehrere Properties für z.B. jeweils ein Verzeichnis anlegen. Noch granularer wird es, wenn man eine Property für genau eine URL – also z.B. eine wichtige Landingpage anlegt. Dann erhält man beispielsweise im Bereich „Content-Keywords“ die wichtigsten Keywords genau für eine URL – sehr hilfreich, um zu eruieren, ob Dein Content thematisch zielgerichtet ankommt.
Content-Keywords-Analyse
Die Content-Keywords-Analyse solltest Du im Übrigen dann regelmäßig auf Domain- oder Pfadebene anschauen. Hier kannst Du nämlich schnell feststellen, ob strukturell etwas im Argen liegt. Die erste Beispielgrafik hier zeigt “versand” und “kostenlos” an erster Stelle – das sind bestimmt keine zielführenden Keywords. Hier ist Optimierungsarbeit angesagt. Die zweite Grafik zeigt eine Auswertung für eine einzelne URL-Property zum Thema “Suchmaschinen-Optimierung”. Hier hat die Optimierung scheinbar geklappt und die relevanten Terme stehen weit oben.


GSC-API für URL-Properties nutzen
Sehr viele URL-Properties auf ein Mal kannst Du übrigens anlegen, wenn Du die GSC-API nutzt. So kannst Du Deine XML-Sitemap einlesen und über die webmasters.sites.add-Funktion hinzufügen. So hast Du schnell alle URLs als Properties hinzugefügt.
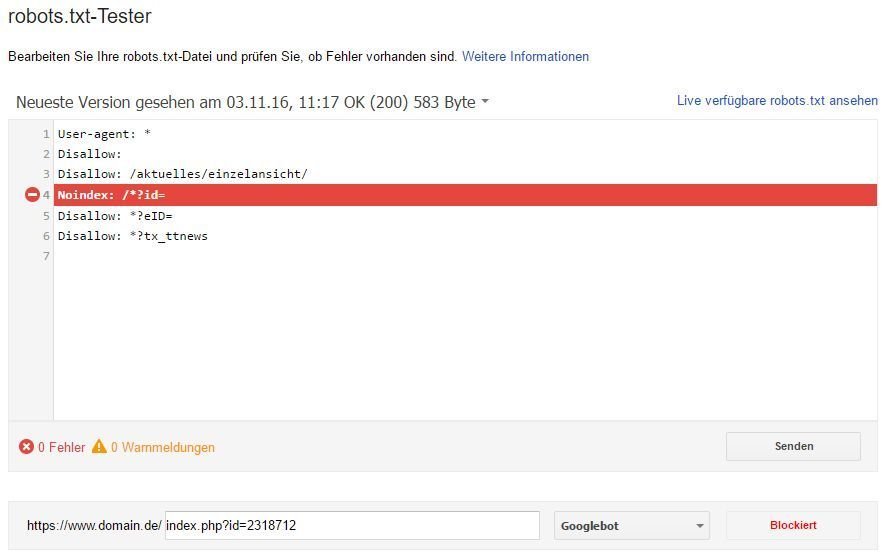
robots.txt-Tester
Viele kennen den robots.txt-Tester. Ein sehr hilfreiches Tool, gerade wenn man komplexere RegExp austesten möchten, bevor man sie live stellt. Viele wissen allerdings gar nicht, dass man auch Zeilen mit „noindex“ in die robots.txt aufnehmen kann. Das entspricht eigentlich nicht dem offiziellen Standard. Die GSC prüft und verifiziert diese Zeilen aber dennoch.
Das ist besonders praktisch und hilfreich bei Parameter-URLs wie im Beispiel. Über FileMatch-Einträge in der .htaccess lassen sich Parameter nämlich nicht behandeln und mit der robots.txt erhält man auch ohne aufwändige Tickets in die IT die Möglichkeit, schnell noindex über viele Seiten auszurollen. Das geht selbst schneller und ist weniger aufwändig, als das HTTP x-robots-Tag zu nutzen.
Ansicht zu interne Links nicht für interne Verlinkungsoptimierung nutzen
Viele SEOs nutzen die Ansicht „Interne Links“ zur Optimierung ihrer internen Verlinkung. Dabei handelt es sich rein um eine quantitative Ansicht. Die GSC unterscheidet nicht nach Platzierung des Links innerhalb des Dokuments. Dabei sind Links aus dem Main Content (MC) sehr viel (ge)wichtiger als Footer- oder Navigationslinks. Auch die Anchortexte sind nicht einsehbar. Fazit: Interne Verlinkung lieber mit eigenen Tools wie ScreamingFrog oder Audisto durchführen und professionelle Metriken aus der Graphenanalyse dafür nutzen. Das wirkt dann auch.
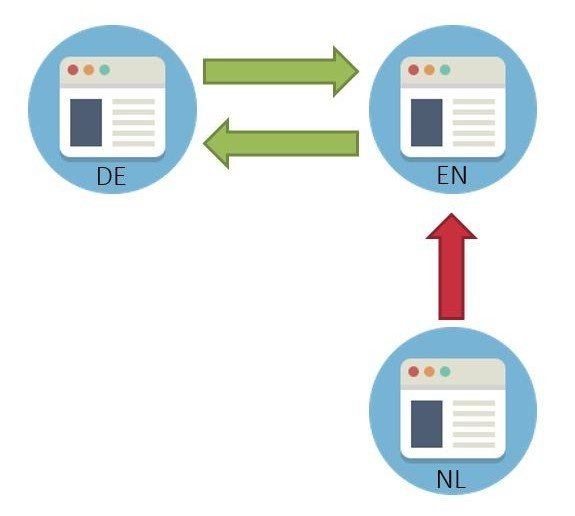
Erkennung von Fehlern der Hreflang-Gruppen nutzen
Bei mehrsprachigen Seiten ist der Einsatz von Hreflang Pflicht. Wer das korrekt macht, spürt fast immer einen deutlichen Rankingboost. Viele Drittanbieter-Tools prüfen allerdings bei der Korrektheit nur die Verlinkung von einer URL ausgehend – also z.B. der DE-Seite zur EN-Seite und zurück. Wenn aber eine wilde NL-Seite in die Gruppe hinein verlinkt, verliert die gesamte Gruppe ihre Gültigkeit, weil es ja keinen Rückverweis dorthin gibt. Die GSC-Ansicht zeigt das entsprechend an – also schau regelmäßig dort hinein und behebe die Fehler!
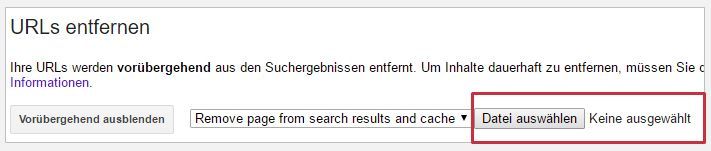
URL-Entfernen ist eigentlich URL-Ausblenden
Glaubst Du auch, dass Du über die „URL-Entfernen“-Funktion wirklich URLs aus dem Google-Index entfernen lassen kannst? Auch wenn der Button vor einiger Zeit so hieß: Man kann URLs nur vorübergehend „ungefähr 90 Tage“ (laut Google-Dokumentation) ausblenden. Das ist ein ziemlicher Unterschied. Denn das Ausblenden findet nur in der Suchanzeige statt. Die URL bleibt weiterhin im Index und zählt somit für die Rankingberechnungen der gesamten Domain mit.
Wenn Du also wirklich eine oder mehrere URLs entfernen möchtest, nutze das noindex! Du kannst ja die URL erst ausblenden und dann gleichzeitig mit einem noindex versehen (über den Meta-Tag, den HTTP x-robots-Tag oder einen Eintrag mit noindex in der robots.txt).
URLs im Bulk ausblenden
Falls Du mehrere URLs gleich zusammen ausblenden möchtest, kannst Du das Bulk-URL-Removal-Script (https://github.com/noitcudni/google-webmaster-tools-bulk-url-removal) verwenden, oder Du nutzt iMacro.
Fast-Disavow zu Zeiten von Realtime-Pinguin
Wenn Du Deine disavow-Liste hochgeladen hast, ist die Entwertung nicht sofort aktiv. Google muss erst noch die betreffenden URLs crawlen. Das kann mitunter Monate dauern - gerade bei nicht sonderlich tollen Quellen. Es gibt ein paar Methoden, wie Du das allerdings beschleunigen kannst:
- Benutze die "Submit URL to Google"-Funktion: Die erlaubt zwar nur die Eingabe einer einzelnen URL jeweils, aber für eine Handvoll ist das eine schnelle Möglichkeit.
- Pingen über pingomatic.com und Co: Hier teilst Du u.a. dem Google-Bot mit, er möge doch bestimmte URLs nochmals besuchen. Früher hat das schneller funktioniert als heute.
- Link-Map über eine dritte Domain: Das muss ich Dir genauer erklären...
Link-Map über eine dritte Domain für Fast-Disavow
Die Variante bei der der Google-Crawler am schnellsten die betreffenden URLs besucht, ist Folgende: Du meldest in der GSC eine neue Domain an. Irgendeine, die Du nicht brauchst. Die nicht ranken soll. Eine verbrannte, alte, blöde Domain.
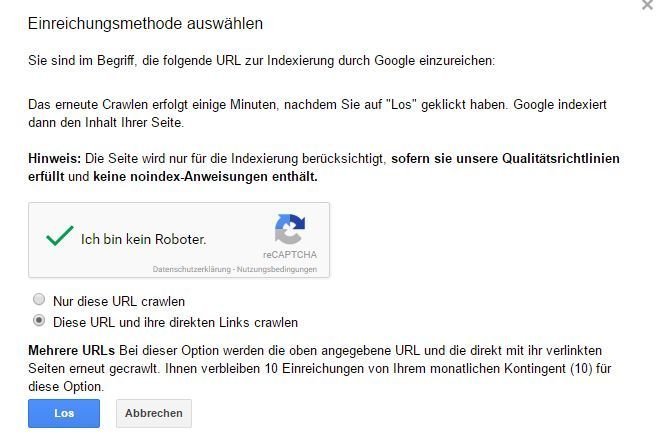
Als nächstes erstellst Du eine HTML-Datei, welche die URLs enthält, die Du disavowed hast. Wrappe die jeweils mit einem Link - egal, was für ein Anchortext. Wichtig ist nur, dass die Datei alle URLs als A-Link enthält.

Diese Datei lädst Du dann auf Deine alte Domain hoch (nicht auf die Projektdomain!). Über die Ansicht "Abruf wie durch Google" kommst Du dann zu einem Popup. Dort wählst Du die Option "Diese URL und ihre direkten Links crawlen" aus. Nach dem Absenden wird der Google-Crawler recht schnell die ganzen URLs besuchen, auch wenn sie nicht auf Deiner Domain liegen. Das Disavow-File wird entsprechend schneller greifen.
Pro Monat kannst Du übrigens nur 10 solcher Submissions je Domain tätigen. Aber eben nur je Domain... :)
Crawlingfehler - trau dich
Viele trauen sich nicht, bei den GSC-Ansichten auf „Als korrigiert markiert“ zu drücken. Das ist gar kein Problem – eigentlich ist es sogar Pflicht. Google zeigt nämlich nicht mehr als 1.000 Fehler an. Du lädst daher alles herunter, sicherst es Dir z.B. in einer Excel-Tabelle. Dann kannst Du beruhigt alles „als korrigiert markieren“. Google wird neue Fehler und alte, noch bestehende Fehler, nochmals dann auflisten. Den Prozess kannst Du wöchentlich durchführen und erhälst so immer mehr Daten.
Gleiches gilt bei externen Links
Kaspar Szymanski meinte in diesem Zusammenhang übrigens in seinem SEOkomm-Vortrag: Wenn Du regelmäßig die angezeigten Backlinks herunterlädst, zeigt Google häufiger eine andere Auswahl an. Leider geht das (noch) nicht über die API, sondern Du musst es händisch, mit Selenium oder mit einem headless-Browser automatisieren.
Verstärktes Crawling ist Hinweis auf Update oder stärkere Rankingänderung
Wenn der Crawler häufiger auf Deiner Site vorbeikommt als üblich, dann macht sich das in der GSC als Peak in der „Pro Tag gecrawlte Seiten“-Ansicht bemerkbar. Meist ist das ein Zeichen dafür, dass ein Google-Update bevorsteht und Deine Site geprüft wird. In dem Beispiel hier handelt es sich um das Pinguin 4.0-Update. Diese Kurve solltest Du immer im Blick haben, da Google viele Updates mittlerweile gar nicht mehr oder verspätet kommuniziert.

Crawlbudget und die GSC-Ansicht
Die GSC zeigt die pro Tag durchschnittlich gecrawlten Seiten an. Häufig werden daraus Schlüsse gezogen, die wie folgt lauten:
„Ich habe 9.000 URLs im Index, Google crawlt ca. 3.000 pro Tag, dann erfasst Google meine Domain innerhalb von drei Tagen komplett neu.“
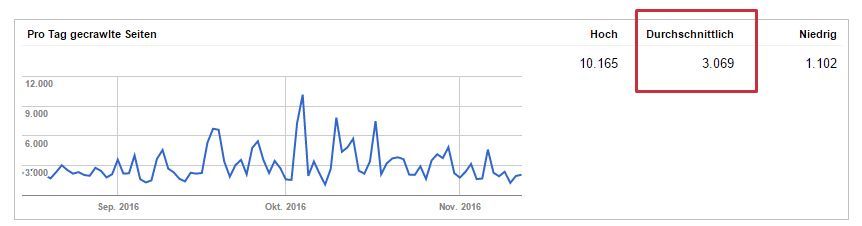
Das ist leider falsch. Die Anzeige der durchschnittlichen Seiten zeigt keine disjunkten URL-Mengen an. Viele URLs werden an einem Tag mehrfach gecrawled, manche auch gar nicht. Eine solche Aussage ist also nicht möglich aufgrund dieser Daten. Hier bleibt Dir nur eine Logfile-Analyse, z.B. mit dem neuen LogfileAnalyzer von ScreamingFrog. Hier kannst Du auch Deine XML-Sitemap mit einlesen und dann die tatsächlichen Crawlmengen mit der XML-Sitemap vergleichen. Sehr praktisch.
GSC Search Analytics – Fakten
Der neue GSC Search Analytics-Bereich ist seit Mai 2015 verfügbar und mit der neuen Search Analytics-API in Version 3.0 auch sehr sehr hilfreich.
Nur 1.000 URLs pro Tag
Laut Google-Dokumentation werden allerdings nur 1.000 unterschiedliche URLs pro Tag gespeichert. Bei großen Domains ist das dann nur ein Bruchteil! Hier solltest Du also auf jeden Fall mehrere Properties einsetzen, um die Daten granularer zu bekommen. Ich habe auf der SEOkomm auch mit John Müller gesprochen. Er meinte, das Datenlimit wäre für große Domains vor ein paar Monaten bereits hochgesetzt worden. Ich konnte das allerdings anhand unserer Domains so nicht verifizieren leider.
1.000er Grenze im Frontend
Auch das Frontend zeigt meist nur 1.000 Datensätze an. Nutze hier auf jeden Fall die API, damit erhälst Du mehr Daten. Oder Du gehst auch hier wieder hin und zerlegst Deine Domain in verschiedene Properties auf Pfad- oder URL-Ebene.
Zeitverschiebung PDT
Bei Analysen, bei denen Tage und Zeiten wichtig sind, solltest Du bedenken, dass die gelieferten Timestamps nach der Pacific Daylight Time (PDT) angezeigt werden. Hier ist eine deutliche Verschiebung zu unserer Zeit in Mitteleuropa: UTC-8! Wenn Du Dich also wunderst, wieso es “komische Daten” um Sonntage und Montage herum gibt, dann liegt das wahrscheinlich genau daran.
Durchschnittliche Rankings
Im Gegensatz zu den zahlreichen Google-SERP-Scraper-Tools, die von allen SEOs so intensiv wegen ihrer Sichtbarkeitskurven genutzt werden, liefert die GSC echte Userdaten aus allen Standorten. Damit erhält man dann nicht nur ein Ranking des Serverstandorts, wo der Scraper gerade läuft. Ein Beispiel macht das deutlich:
Ein Pizzalieferdienst ranked für das Keyword „pizzalieferdienst“ in Hamburg auf Position 1, in Köln auf Position 6 und in München auf Position 3. Die durchschnittliche Position, welche in der GSC angezeigt wird, errechnet sich aus (1+6+3) / 3 = 3,3. Das solltest Du in Deinem Mindset zum Thema Rankinganzeigen immer bedenken!
Gewichtete durchschnittliche Position
Bei aggregierten Ansichten kommt es dann auch zu den sogenannten gewichteten durchschnittlichen Rankings. Das findet man spannenderweise gar nicht so ausführlich in der GSC-Dokumentation. Was bedeutet gewichtet? Die Rankings werden nach Anzahl der Impressionen wichtiger oder weniger wichtiger. Ein Beispiel:
Wenn ein Keyword 1.000 Impressionen auf Platz 1 erhält und nur 50 Impressionen auf Platz 7, dann ist wird das gewichtete durchschnittliche Ranking in der GSC so berechnet:
(1.000 * 1 + 50 * 7) / 1.050 = 1,28.
Obacht bei der Wahl der Analyse: Seiten vs. Suchanfragen
Wusstest Du, dass Google einen Unterschied macht zwischen Seiten und Suchanfragen bei den Mehrfachrankings? Ein Mehrfachranking hat fast jeder – nämlich in Form von Sitelinks.
Bei der Ansicht „Seiten“ in der GSC zeigt Google die seitenbezogene Auswertung an. D.h. jede URL, die Hauptdomain und die Sitelinks, erhalten eine Impression. Bei der Ansicht „Suchanfragen“ erhält nur die gesamte Domain eine einzige Impression, nicht die einzelne URL. Ähnliches gilt dann auch für die Klicks. Am besten schaust Du Dir nochmal genau die GSC-Google-Doku dazu an.

Bereinigung der Suchdaten
Google bereinigt für den Import der GSC die Suchdaten sehr gründlich. Hier fallen rechtswidrige, pornografische und auch datenschutzkritische Daten heraus. Nicht sehr gut dokumentiert ist die Tatsache, dass in der zusammengefassten Ansicht direkt unter der Filteransicht die unbereinigten (!) Datensummen stehen. In der Tabelle darunter (auch über die API) werden allerdings die bereinigten Daten angezeigt. Das merkst Du dann, wenn Du mal die Summen aus der Tabelle zusammenzählst und dann nicht auf die Summen oben kommst. Normal – leider. Ein (not set) wird hier nicht angezeigt. Die Summen stimmen leider einfach nicht überein.
Mehrfachranking und Schwellenkeywords
Ein häufiger Optimierungseinsatz für die Search Console-Daten hat mit Mehrfachrankings zu tun. Mehrfachrankings treten dann auf, wenn für eine Suchanfrage mehrere organische Treffer einer Domain sichtbar sind.
Vor allem in den Positionen 3-10 ist das meist ein Zeichen, dass Google sich nicht so recht sicher ist, welche URL die bessere ist. Manchmal wird dann auch abwechselnd nur eine URL angezeigt, das bezeichnet man dann als Switcher. Bei den Mehrfachrankings treten meist zwei URLs auf. Das Schöne ist: Wenn Du eine URL optimierst und die andere etwas de-optimierst, dann ranked danach nur noch eine – und zwar meist auf einem besseren Ranking als vorher die beiden zusammen! Optimiere also Deine Mehrfachrankings (das kannst Du übrigens mit dem serplorer sehr einfach und schön tun, der zeigt Dir die Mehrfachrankings an).
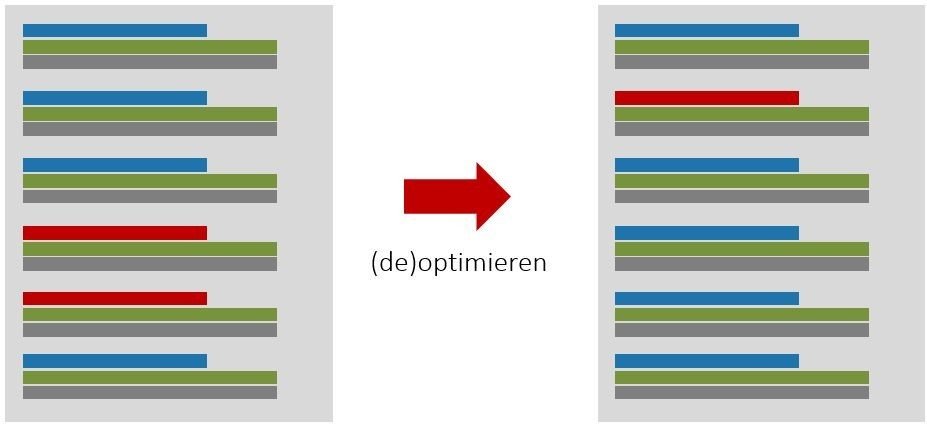
Schwellenkeywords optimieren
Ähnlich schnell kannst Du Rankings identifizieren, die auf Position 11 bis 15 hängen. Wenn man diese Schwellenkeywords auf die erste SERP-Seite optimiert, dann bekommt man meist deutlich mehr Klicks. Einfach und wirkungsvoll. Mit der GSC ist sehr viel mehr möglich: SERP-Snippet-Testing, Google Ads-Vergleiche, Landingpage-Optimierung bei Shops, Linkmonitoring und viele andere Dinge. Mehr praktische Einsatzzwecke findest Du übrigens bei den Kollegen von takevalue und den TrustAgents.
Die Google Search Console-API
Die GSC-API in Version 3 ist sehr hilfreich und jeder SEO, der ernsthaft mit Daten arbeitet (und das sollte eigentlich jeder), kommt nicht um die API herum. Warum? Weil sie einerseits deutlich mehr Daten zur Verfügung stellt als das Frontend und weil nur mit einer API Prozesse gestaltbar sind, die auch skalieren.
Die GSC API ist in vier Bereiche unterteilt:
- Der searchanalytics-Bereich stellt die Suchdaten zur Verfügung und hat die komplexeste Abfragelogik.
- XML-Sitemaps kann man verwalten
- Properties kannst Du ebenso anzeigen, anmelden und löschen
- Crawlingfehler und Crawlingbeispiele stehen auch über die API zur Verfügung
Mehr Details findest Du direkt bei Google: https://developers.google.com/webmaster-tools/v1/api_reference_index.
API-Explorer nutzen
Für die ersten Schritte in der GSC-API empfehle ich jedem den Google API Explorer. Hier kann man frei und ohne Programmieren mit der API experimentieren und schnell zum Ergebnis kommen, bevor man das dann mit Python, PHP oder anderen Sprachen in feste Code-Strukturen gießt. Übrigens ist die OAuth2.0 gerade für die vielen Hobby-Entwickler dabei die größte Hürde. Da empfehle ich entweder professionelle Entwickler oder ein Getränk Deiner Wahl und ein “bisschen” Dokumentations-Lesen zur Weiterbildung.
Abfragelimits bei der Google Search Console API
Google schreibt recht klar über Abfrage-Limits (https://developers.google.com/webmaster-tools/limits) der API. Im SearchAnalytics-Bereich sind es maximal 5 Abfragen pro Sekunde. In der Praxis schafft man allerdings eher weniger. Hier solltest Du Dir mal auf jeden Fall den Parameter quotaUser anschauen und den für die Abfragen alternierend verwenden. Bei großen Datenmengen nutzt man am besten die GZIP-Komprimierung. Auch das Partial Response, also die Funktion, nur bestimmte Teile im Ergebnis-JSON zu bekommen, spart Zeit.
Wenn man einen sogenannten rety-able-error erhält – weil man zu schnell abgefragt hat – dann sollte man nicht einfach nur stupide ein paar Sekunden warten. Google setzt einen „expontenial backoff“ ein, d.h. mit jeder zu schnellen und geblockten Abfrage erhöht sich die Wartezeit exponentiell. Das kann ordentlich schief laufen. Daher nutze die Formel:
(2^n) * rand(0-1000).
GSC-API ohne Programmierkenntnisse
Auch ohne Programmierkenntnisse kann man sich der API bedienen und somit mehr Daten erhalten.
Die SEOTools für Excel stellen in der kostenpflichtigen Pro-Version eine Anbindung da, die allerdings derzeit (noch) nur das alte Zeilenlimit von 5.000 beherrscht. Das reicht für kleinere Accounts aber allemal. Wer lieber mit Google Sheets arbeitet, der hat mit der Chrome-Erweiterung SearchAnalyticsForSheets richtig viel Spaß. Hier kann man alle relevanten Einstellungen machen und auch Parameter wie Query und Page zusammen abfragen.

Not-Provided gelöst
Die Auswertung Query-Page Auswertung ist besonders spannend, da man mit ein bisschen Pivot-Arbeit in Excel oder Google Sheets selbst sich URLs anzeigen lassen kann und die dazu rankenden Keywords. Damit ist das Not-Provided-Problem aufgehoben. Wenn man die Reihenfolge von Page-Query umdreht, erhält man automatisch Mehrfachrankings. Wem das alles zu viel Arbeit ist, der kann dafür auch den serplorer nutzen. Da geht das alles auf Klick automatisch mit diversen Filtermöglichkeiten.
Urlcrawlerrorsamples als Prozess etablieren
Wer ordentlich SEO macht, arbeitet eher früher als später mit Prozessen für die regelmäßige Optimierung. Die Crawlfehler können auch über die API gezogen werden. Sehr praktisch – weil hier auch gleich die verlinkenden URLs mit aufgelistet sind, die man sich im Frontend sonst nur mühsam zusammenklicken kann. Diese Daten kannst Du in eine Datenbank packen und eine eine ToDo-Liste daraus generieren. Schon bist Du einen guten Schritt weiter in Sachen Website-Hygiene, Index-Sauberkeit und Verwertung von verschwendetem Linkjuice.
GSC-Tweak: Nicht indexierte URLs über die GSC anzeigen lassen
John Müller von Google antwortete auf der SEOkomm auf die Frage, ob die GSC jemals anzeigen würde, welche URLs NICHT indexiert sind mit einem klaren „nein“. Dabei ist es für jeden SEO sehr wichtig zu wissen, welche URLs indexiert sind und welche nicht. Denn erst wenn etwas indexiert ist, kann es ranken. Und wenn man weiß, dass bestimmte Verzeichnisse und Bereiche nicht indexiert werden, kann man entsprechend gegensteuern – also den Content aufwerten, die interne Verlinkung optimieren, die Ladezeit verbessern oder andere Optimierungen durchführen.
Es gibt allerdings einen Trick, wie man sich in der Search Console auch die nicht indexierten URLs anzeigen lassen kann. Voraussetzung dafür ist eine vollständige und aktuelle XML-Sitemap. Das sollte aber ohnehin Pflicht sein und mit jedem guten CMS automatisch erstellt werden.
Der GSC-XML-Tweak
Der „Trick“ besteht darin, dass man eine normale URL-XML-Sitemap in eine Index-XML-Sitemap umwandelt, die jeweils wieder auf URL-XML-Sitemaps verweist. Allerdings beinhaltet jede einzelne URL-XML-Sitemap nur eine (!!!) URL. Diese Dateien läd man dann auf den Server hoch und meldet sie in der Search Console an. Das sieht dann so aus:
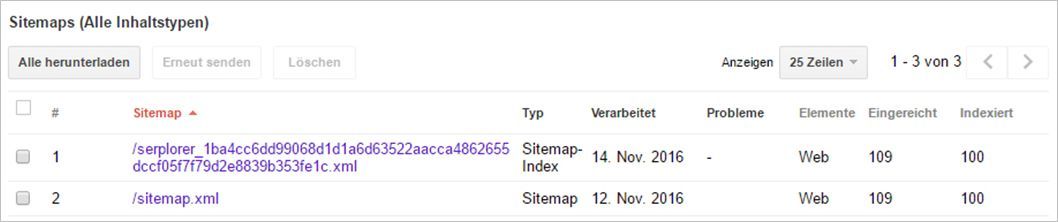
Klickt man nun auf die Sitemap-Index, dann stellt die GSC eine Detailansicht zur Verfügung. Hier kann man nach einer gewissen Verarbeitungszeit dann genau sehen, welche URLs zwar eingereicht wurden, aber noch nicht indexiert sind (rote Pfeile). Deswegen darf man in der URL-XML-Sitemap auch nur eine einzige URL einfügen!
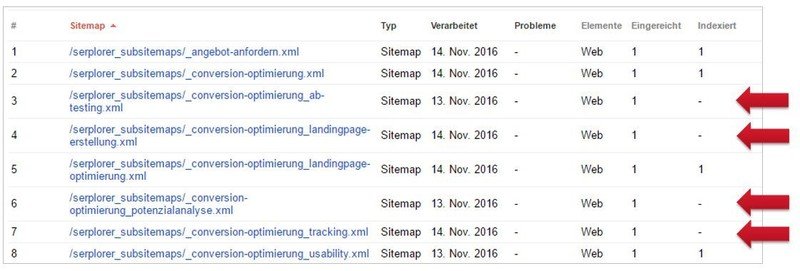
Wenn man nun noch einen Schritt weitergeht, dann kann man die einzelnen Daten auch noch zu Pfaden aggregieren und sehen, welche Bereiche auf einer Website nicht gut indexiert sind und wo noch Nachholbedarf ist. Wem diese ganze Konvertierung zu kompliziert ist – seit Ende November gibt es genau diese Funktion beim serplorer für alle registrierten User.
Ich hoffe, es waren ein paar neue Informationen für Dich dabei. Viel Spaß und Erfolg damit!
Für ganzheitlichen Erfolg im Online Marketing
SEO Consulting
Wir helfen Ihnen dabei, Sichtbarkeit in Suchmaschinen zu erlangen und mehr qualifizierte Besucher:innen auf Ihre Website zu führen. Dafür legen wir uns ins Zeug – mit Leidenschaft, geballtem Know-how und über 19 Jahren Markterfahrung als SEO-Agentur. Bereits seit 2002 unterstützen wir Kund:innen im Bereich Suchmaschinen-Optimierung.
Content-Kreation
Ihr digitaler Erfolg entsteht durch kreative Inhalte, die Ihre Website-Besucher:innen informieren und begeistern. Als erfahrene Agentur für Content-Kreation entwickeln wir eine Strategie für Ihr Content Marketing, die auf Ihr Unternehmen und Ihre Zielgruppen zugeschnitten ist. Im Zentrum stehen die richtigen Inhalte an der richtigen Stelle Ihrer Website.
Webauftritt optimieren
Als zentraler, virtueller Berater entwickeln wir gemeinsam mit Ihnen Ihre performante, individuelle und professionelle Website. Unsere Website Services reichen dabei von der strategischen Konzeption über ein ästhetisches, funktionales UX/UI-Design und die individuelle Entwicklung bis hin zur laufenden technischen Website-Betreuung.


